[RL-reinforce]: learningrate exp #1 #37
Open
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
Experiments on reinforce algorithm, trying to figure out why entropy is collapsing and policy converges too quick to a actions with prob = 1.
Here we are changing learning rate and observing behavior on entropy, loss, and running reward.
After 30.8k steps episodes, model managed a maximum Running Reward of ~590 @27k episode. We achieved best performance are using LR of 1e-05.
Explanation and conclusions below.
tested learning rates
05e-04 orange / 01e-04 seablue / 01e-05 green / 01e-06 pink / 01e-08 skyblue
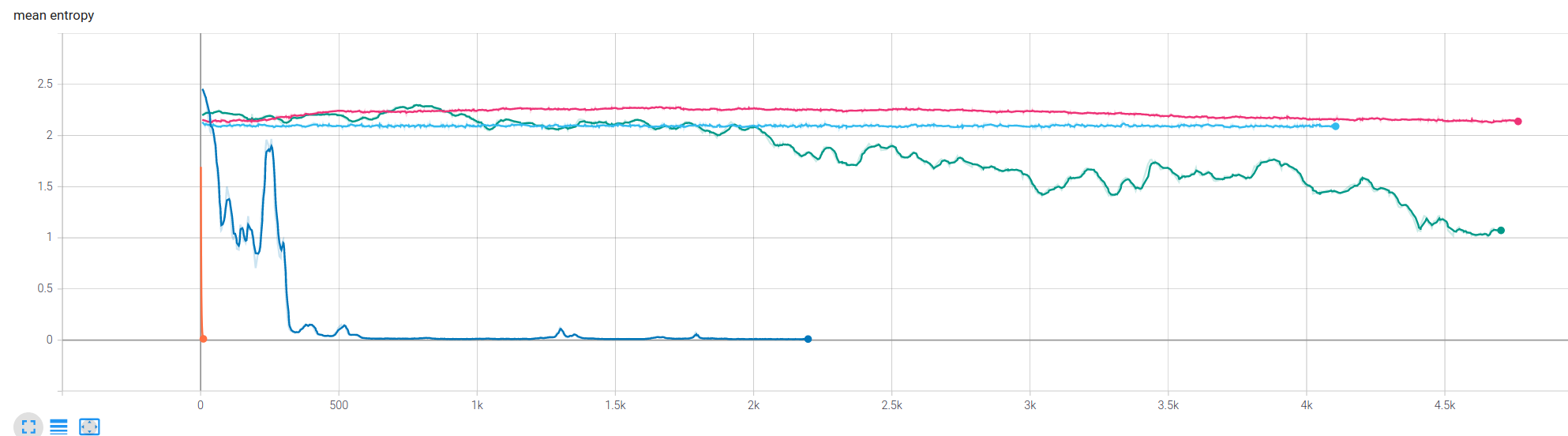
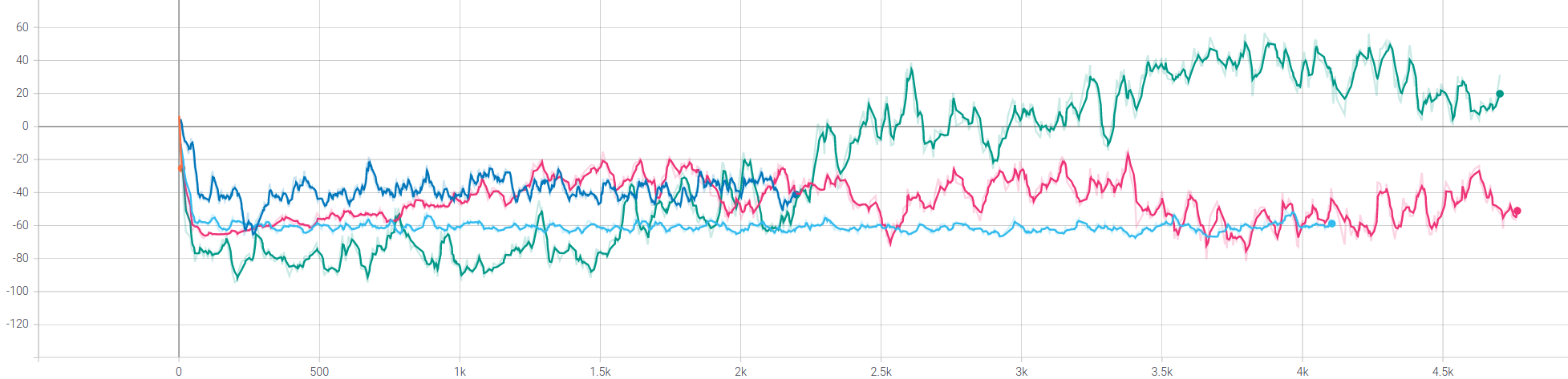
Note:
From that starting point, we decided to extend training time using 01e-05 lr. Results below
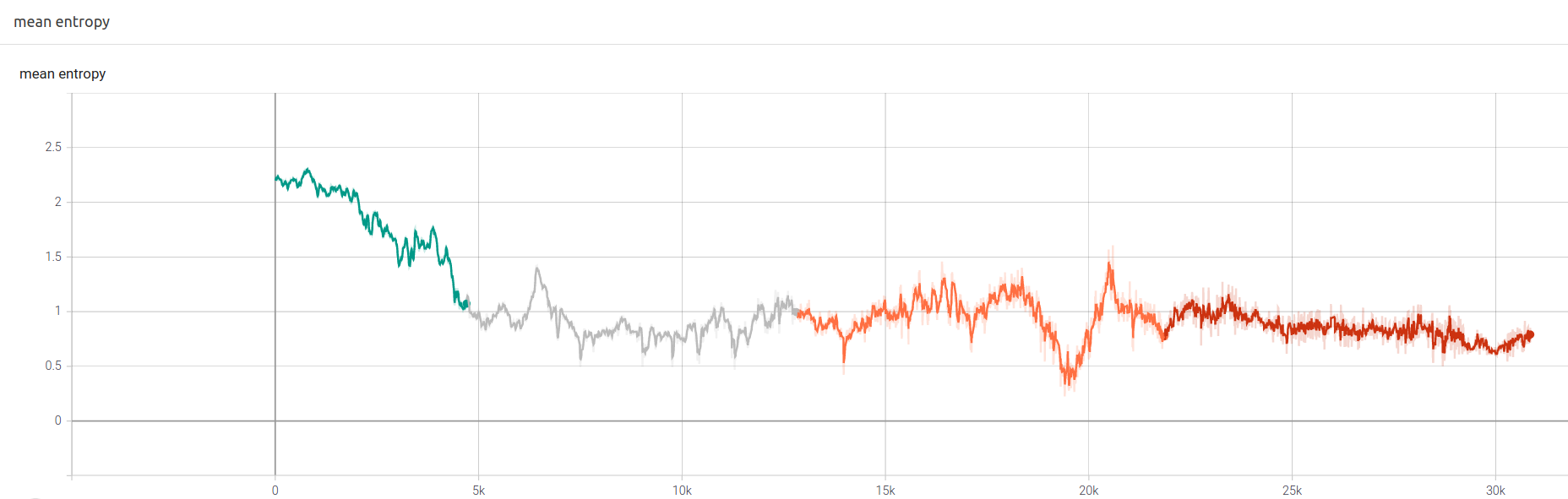
At this point, we can sometimes get rewards up to 810. Agent is even capable of recovering from massive donuts burnout.
openaigym.video.0.32231.video000000.mp4
Reinforce may be able to solve CarRacing environment but still has many weak points:
We need to use small learning rate to avoid policy being stuck and not learning.
As a result of using small learning rate, training is very slow.
Not sure yet if we will reach our target using reinforce algorithm (Running reward = 900)
Other approaches and extensions of basic reinforce should show better results.