Fix regressions from 3.1.4 #530
Conversation
There was a problem hiding this comment.
Thanks for the PR!
This matches: background-image: 'url(javascript:alert("XSS"))' which we probably don't want. https://regex101.com/r/vVInfw/1
Also, there's overlap in the match groups so it might be vulnerable to ReDoS too.
|
Thanks for the feedback. |
Good call. That'd be great! We should also test I'd like to have a lot more "bad CSS" testcases before making the regex more permissive in a stable release (we could push a dev release in the meantime), since I don't have context around the original CSS filtering.
Yes, please limit this PR to fixing the dashed attributes regression / #529.
The ReDoS in GHSA-vqhp-cxgc-6wmm (with https://bugzilla.mozilla.org/show_bug.cgi?id=1623633#c0 for context) exploited the overlap in |
|
The pre-3.1.4 code had the problem of matching Note that all discussion seems to be about the the last changeset. The 3 first changesets are already limited to fixing the dashed attributes regression. Could we agree on the 3 first changesets and land them? The discussion of the 4th changeset seems to be about not undoing some 3.1.4 changes that wasn't mentioned in commit message or Changelog. Since there hasn't been any claims of fixing any sanitize bugs, I would expect the ideal would be to get behaviour back to the pre-3.1.4 state but with the ReDoS fixed. I don't think this PR is making things more permissive. It is just fixing some things that 3.1.4 broke, while still leaving it much less permissive than 3.1.3 was. For the 4th changeset: |
|
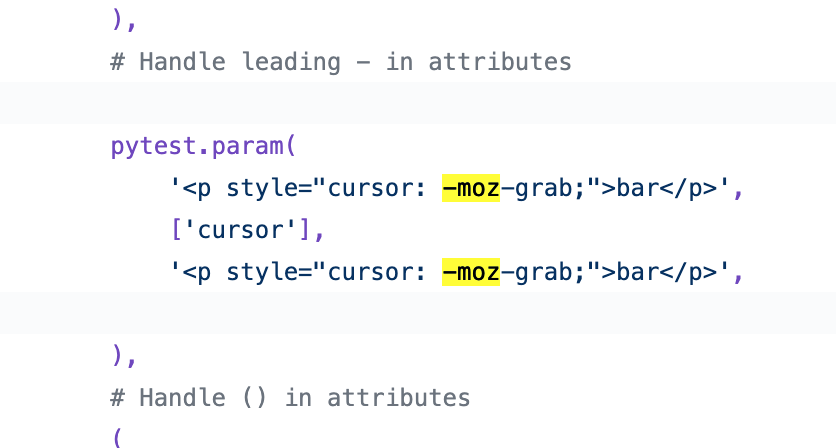
Hi there, will this PR also include values with hyphens? e.g. KaTeX generates HTML like this to represent super/subscript. If so, should the test include an example of a negative CSS value as well? |
|
There was already a test of |
|
@kiilerix You are correct! I see it now. Thank you
|
|
Looking at this again, I still think my full PR is safe and an improvement. As a minimal first step, the 3 first changesets do what g-k agreed on for fixing the For fixing other 3.1.4 regressions, I still wonder what security issues it is trying to block. It seems like it would have been better if 3.1.4 just fixed the DoS by removing superfluous regexp options: That will not make it more permissive than 3.1.3 was but will just fix the 3.1.4 regression. Going back to this will thus be very suitable for a stable 3.1.6 release. But as a next step I will now propose something more drastic: I don't see how CSS values for whitelisted CSS attributes (in HTML that already has been parsed) ever can be dangerous in reasonably modern and wellbehaving browsers. It seems to me like the whole gauntlet check safely could be dropped. (I can see how values with unquoted |
|
We also were hit by this regression. Is there any traction on this PR? |
I don't know. It is unclear if the project owners had any undeclared intents with the 3.1.4 regressions. It seems like it is a big concern to avoid emitting |
|
@kiilerix can you rebase? |
Rework d6018f2 and choose an alternative approach to fixing bug 1623633. Before that change, '-' could be matched either by itself, or by '\w-\w'. The latter seemed to have the odd intent of avoiding leading or trailing '-' ... but also meant it allowed 'a-aa-a' but not 'a-a-a'. The primary intent with the change seemed to be to avoid a backtracking explosion exploiding the ambiguous matching of '-'. The chosen solution of allowing '\w-\w' but not '-' broke some tests and some real world use cases. There doesn't seem to be any risk from allowing leading or trailing or consecutive '-' in styles. Thus, instead, this change will choose the path of allowing '-' as a normal character and drop the special handling of '\w-\w'.
Rework d6018f2 and choose an alternative approach to handling ' and " while fixing bug 1623633. Before that change, ' and " could be matched either by themselves, or balanced around [\s\w]+ . The intent with the change seemed to be to avoid a potential backtracking explosion exploiting the ambiguous matching. The chosen solution of for example allowing 'foo' and "foo bar" but not 'foo-bar' broke some tests and some real world use cases. There doesn't seem to be any risk from allowing any of the "usual" characters inside balanced quotation marks. This change will expand the set of valid strings inside quotation marks without adding any ambiguity that can cause backtracking. We will accept all the characters that already are allowed outside quotation marks, but also accept the other kind of quotation marks, allow ( and ) , and empty strings.
Agreed. The gauntlet regex was added to bleach when it was a concern, but we can drop support for legacy browsers instead of continuing to tweak the regex. |
|
I'd like to close this out and move forward with @g-k's idea in #530 (comment) . I think that'll be a lot better for everyone. |
|
Nice to see some progress, one way or another ;-) I subscribed to #627 . Is that the way to follow how it works out? |
No description provided.