QuantConv2D binarized activations with tf.int32 bitpacked output #611
Conversation
- strips the output LceDequantize operators of a model such that the output is a bitpacked tf.int32 tensor - usually the lce_converter dequantizes the bitpacked output back to tf.float32 resulting in an identity tensor - use cases: larq.layers.QuantConv2D followed by a sign operation (ie. larq.math.sign or larq.quantizers.SteSign()) - import using `from larq_compute_engine.mlir.python.util import strip_lcedequantize_ops`
|
@simonmaurer Thanks for the PR 🎉 Could you also add a small unittest for this functionality? |
|
so the conversion works as seen on the following pictures:
I realized that the error check conditions are never met if the model has TF quantized inputs/outputs (
In that case these checks are not necessary, or am I missing something here? |
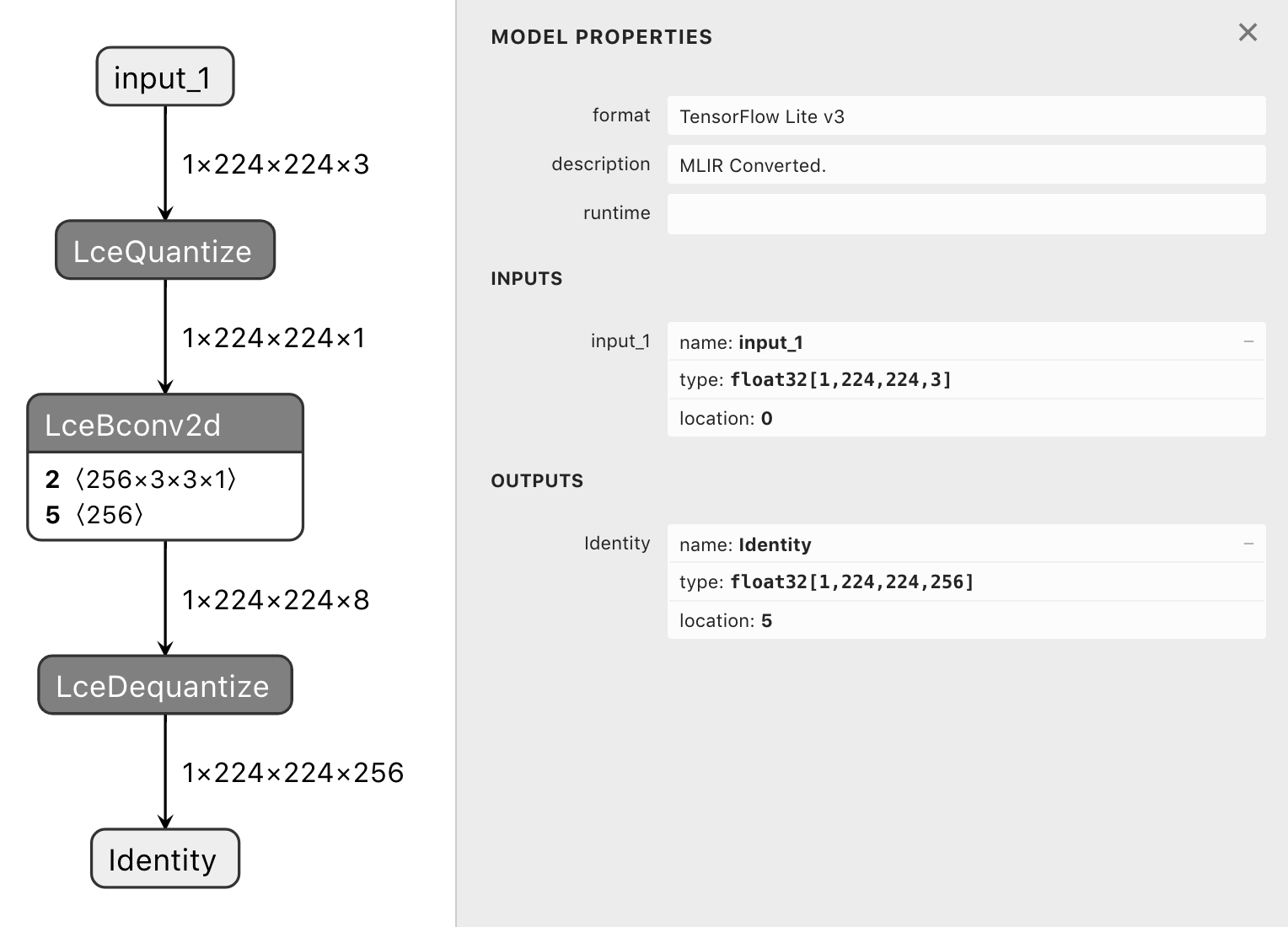
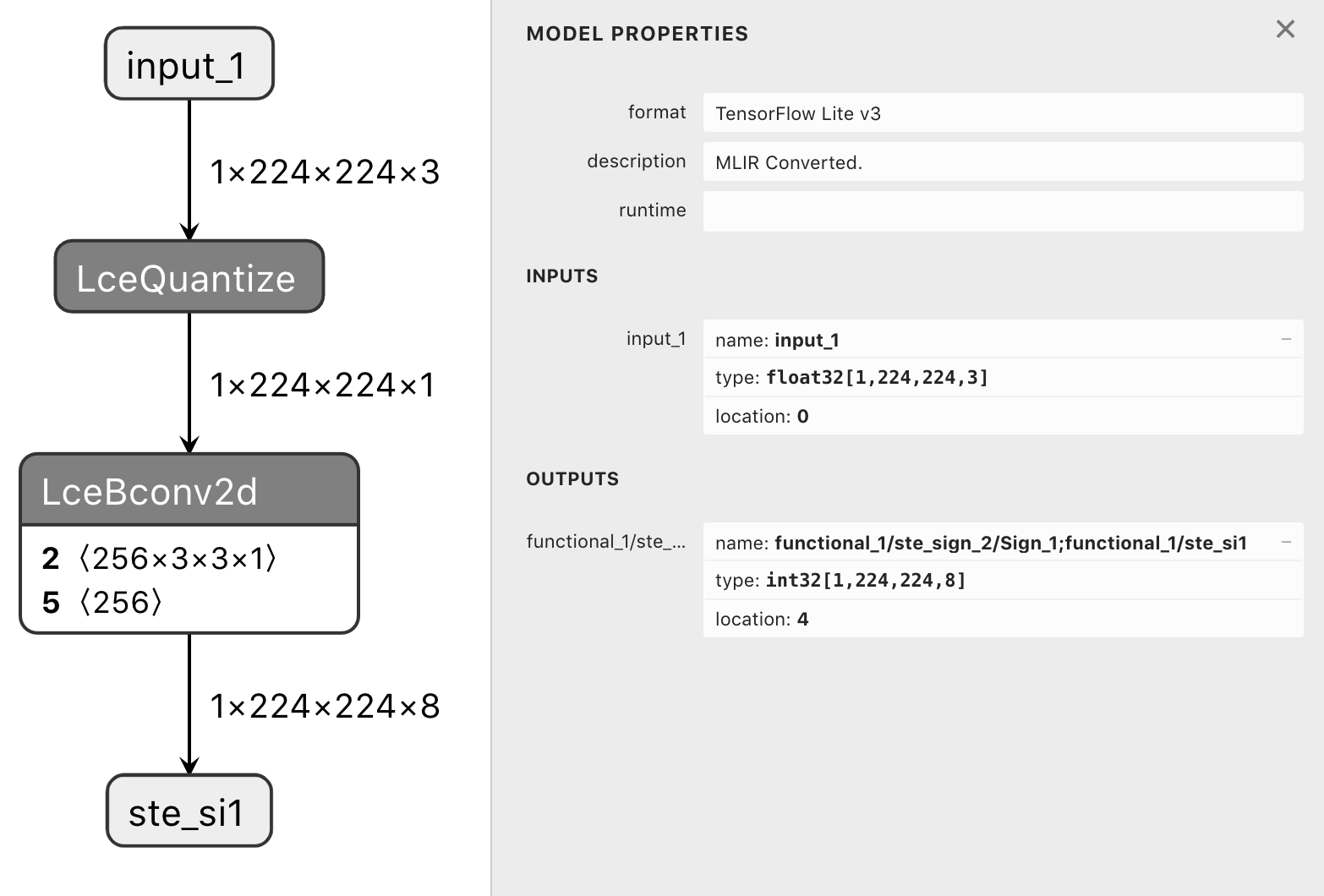
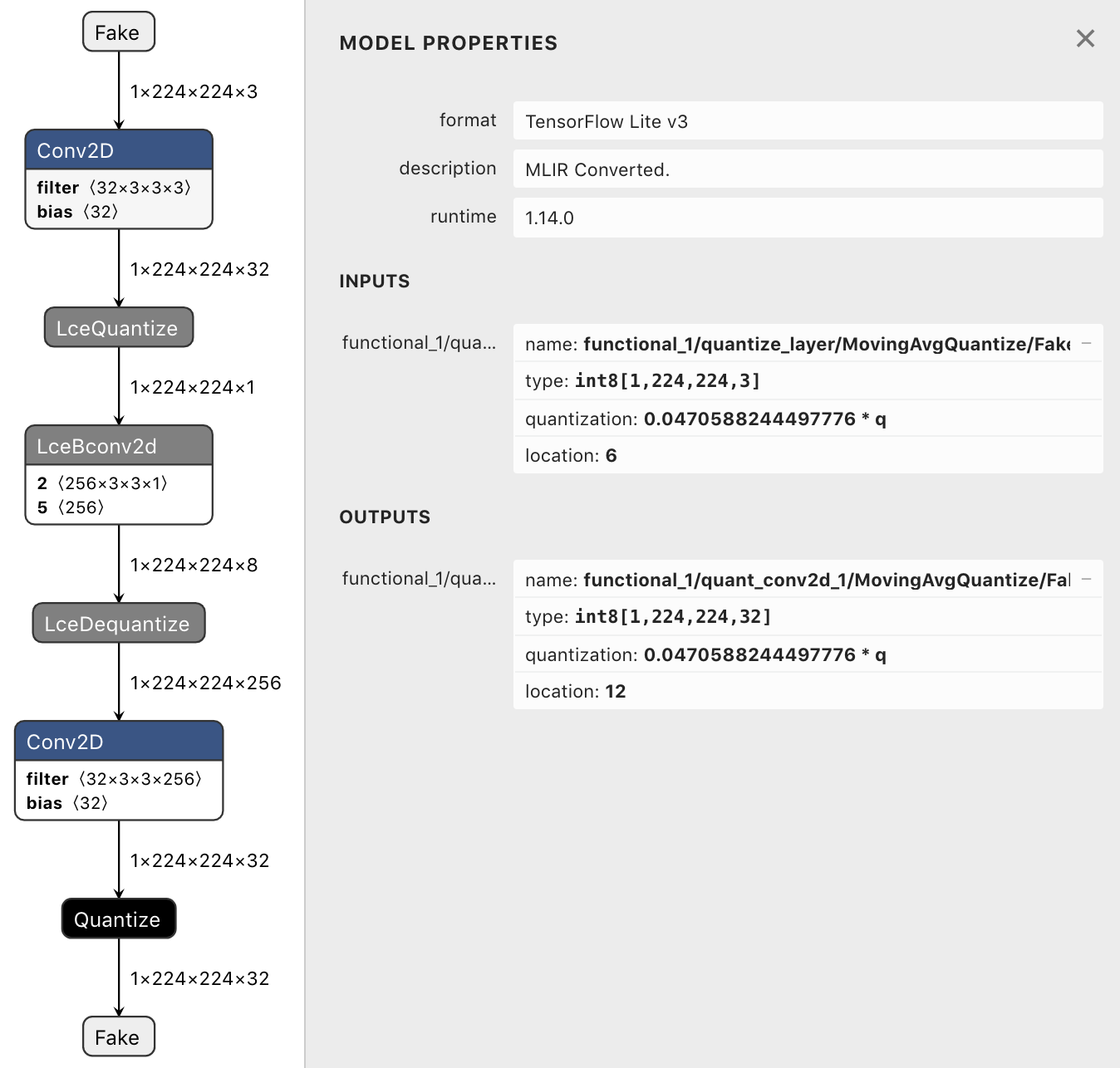
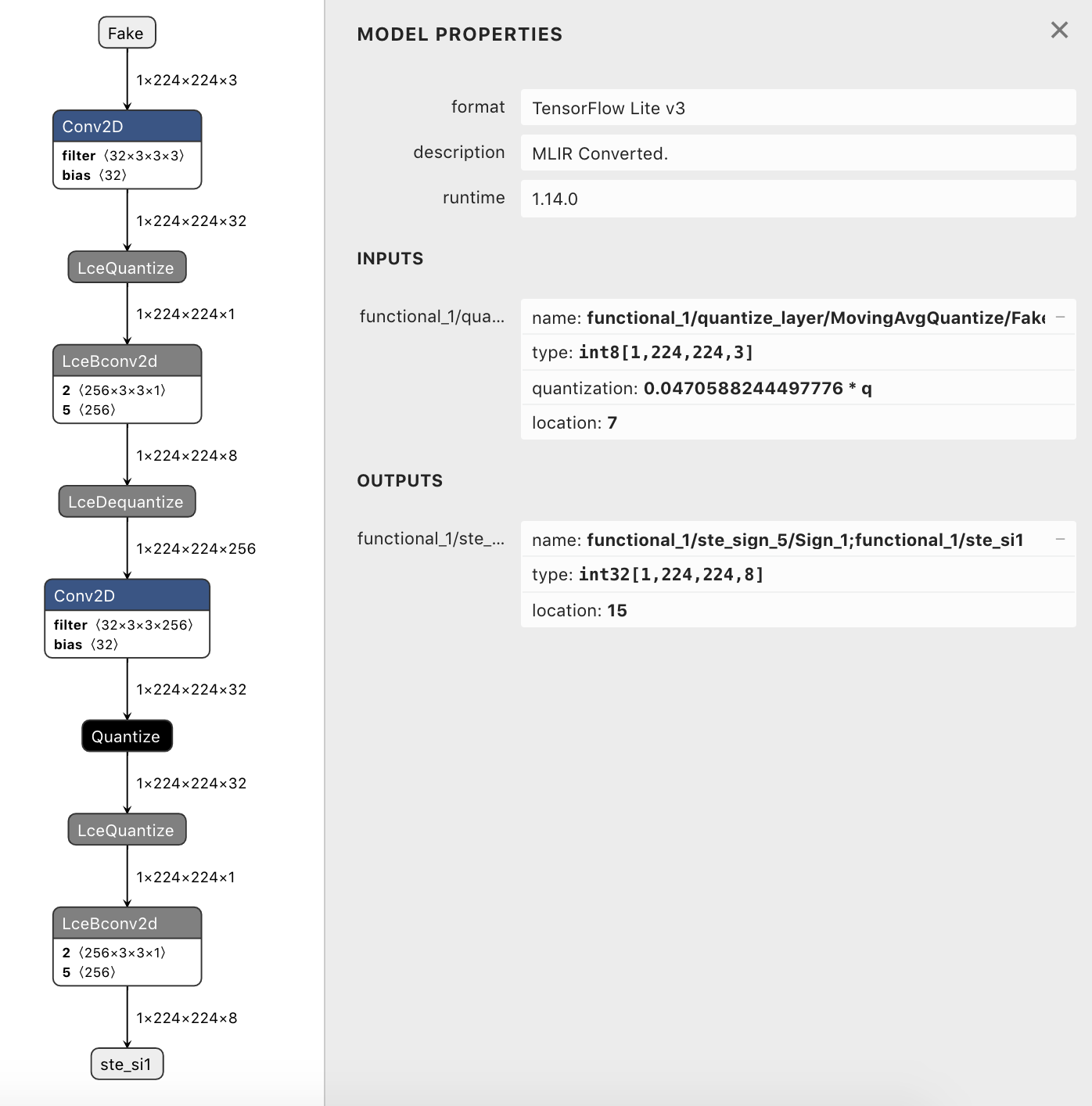
|
sidenote on the thing is if there are no |
|
Sorry for the late reply.
To be honest, I am not 100% sure about this. This code was originally adapted from tensorflow/tensorflow@ec94fab but it looks like there've been additional changes in the latest version which would be great to apply here as well in another PR. Could you still add a unittest similar to this one that tests that the functionality works as expected? |
@lgeiger sorry for the delay. |
|
Thanks for adding the test. Could you check the linting errors on CI? It looks like larq_compute_engine/tests/strip_lcedequantize_test.py:3:1 'larq as lq' imported but unused
larq_compute_engine/tests/strip_lcedequantize_test.py:4:1 'numpy as np' imported but unused
larq_compute_engine/tests/strip_lcedequantize_test.py:10:1 'larq_compute_engine.tflite.python.interpreter.Interpreter' imported but unused
larq_compute_engine/tests/strip_lcedequantize_test.py:15:9 undefined name 'larq'
larq_compute_engine/tests/strip_lcedequantize_test.py:16:9 undefined name 'larq'
larq_compute_engine/tests/strip_lcedequantize_test.py:25:9 undefined name 'larq'
larq_compute_engine/tests/strip_lcedequantize_test.py:26:9 undefined name 'larq'
larq_compute_engine/tests/strip_lcedequantize_test.py:39:69 undefined name 'toy_model' |
|
@lgeiger fixed all import errors, reformatted code using black code style. |
There was a problem hiding this comment.
@simonmaurer Sorry for the delay in reviewing this. I just rebased your PR onto master and added the unittests to our CI infrastructure in da432fd
Let's get this merged once CI passes 🚀
- strips the output LceDequantize operators of a model such that the output is a bitpacked tf.int32 tensor - usually the lce_converter dequantizes the bitpacked output back to tf.float32 resulting in an identity tensor - use cases: larq.layers.QuantConv2D followed by a sign operation (ie. larq.math.sign or larq.quantizers.SteSign()) - import using `from larq_compute_engine.mlir.python.util import strip_lcedequantize_ops`
…instead of tf.lite
| if inference_output_type == tf.float32: | ||
| assert output_details[0]["dtype"] == tf.int32.as_numpy_dtype | ||
| else: | ||
| assert output_details[0]["dtype"] == inference_output_type.as_numpy_dtype |
There was a problem hiding this comment.
Does this mean if output inference type is tf.int8 the dequantize op is not removed?
@simonmaurer Is this intended behaviour?
There was a problem hiding this comment.
yes, this is intended behavior.
as discussed here:
Sorry for the late reply.
In that case these checks are not necessary, or am I missing something here?
To be honest, I am not 100% sure about this. This code was originally adapted from tensorflow/tensorflow@ec94fab but it looks like there've been additional changes in the latest version which would be great to apply here as well in another PR.
I would need to take a closer look if these errors would ever be thrown here, but if you think they won't, fell free to remove the checks for them instrip_lcedequantize_ops.Could you still add a unittest similar to this one that tests that the functionality works as expected?
I do understand that you manually verified that the code works, but it is important for us to have these checks also run on CI so we can ensure that it also works with older versions of TensorFlow and crucially that the code will keep working and we don't accidentally break it in a future PR.
and when looking at the graph of tf.float32/tf.int8 models there are only LceDequantize ops when the model has tf.float32 outputs.
in other words the LceDequantize ops are removed (resulting in the desired tf.int32 outputs) iff the model has tf.float32 outputs
There was a problem hiding this comment.
actually it shouldn't differ..as long as there are LceDequantize ops as outputs they should be removed to get tf.int32 outputs, no matter what tf.float32/tf.int8 ops are inside the model
since you've pointed this out: I've removed this check for tf.int8 models in the unittest function with the last commit, but actually it could (or should) still be in there. not sure though why the MLIR test did not go through for tf.int8 output models..
There was a problem hiding this comment.
MLIR failed again for the assertion tests
There was a problem hiding this comment.
You might also want to apply similar changes as done in #635 to this PR, but I don't think this will fix CI either. Looks like the dequantize node is not correctly removed in your example.
deactivate setting default int8 ranges for `tf.float32` models as the strip_lcedequantize_ops function will not remove `LceDequantize` ops
There was a problem hiding this comment.
@lgeiger after inspecting the unittest code again, I deactivated the default int8 ranges for tf.float32 models. as you said the function strip_lcedequantize_ops would never remove the LceDequantize ops since any model that was generated via the parametrized pytest functions resulted in tf.int8 outputs
sorry if this didn't make it into the v0.6 release..didn't know your time schedule. it's been taking a while since I always thought I had to recompile everything. the code works for |
No worries, we can always push a patch release later.
This should now be a bit better since we are now relying on a stable TF version so bazel should be able to properly cache the build artifacts. |
Testing strip_lcedequantize_ops for tf.float32 output: - fix double allocation of Interpreter, using tf.lite.Interpreter instead - fix typo when converting model to TFLite model
|
@lgeiger testing |
removed import of Larq interpreter due to Lint tests failing
- only validate output after LceDequantize ops have been stripped, input type tests already validated in end2end_test.py
fix: setting inference_input_type statically to tf.float32 as we're only validating the output
- updated signature defs for TF2.5 compatibility - support int8-quantized models when stripping LceDequantize op for int8 output - support int8-quantized models when using dequantized tf.float32 output, strips Dequantize operator first then LceDequantize
|
@lgeiger @AdamHillier finally the Unit tests work for both tf.float32 and tf.int8-quantized models. additionally I had to adapt the code to the following cases.
Overall we have:
|
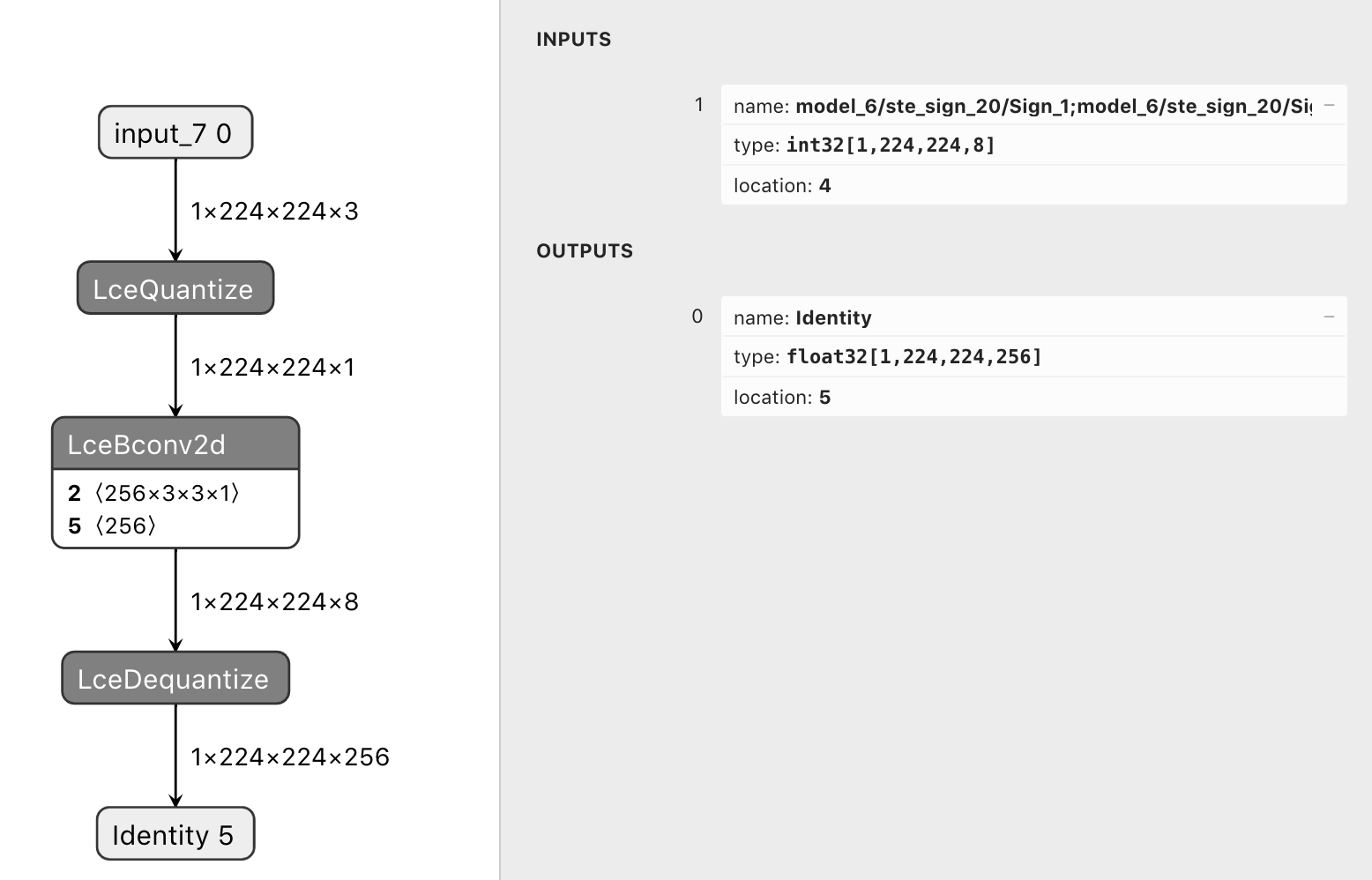
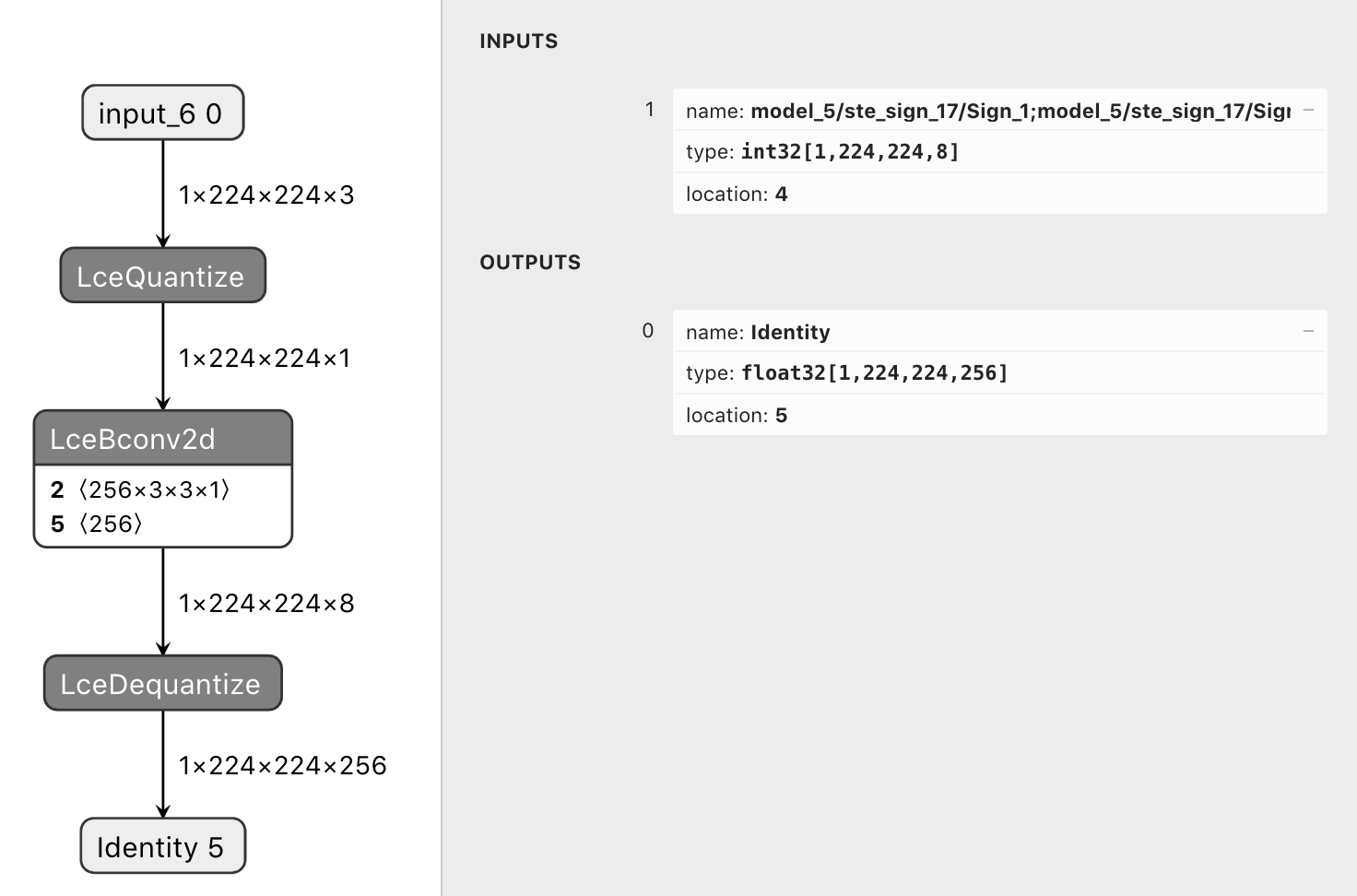
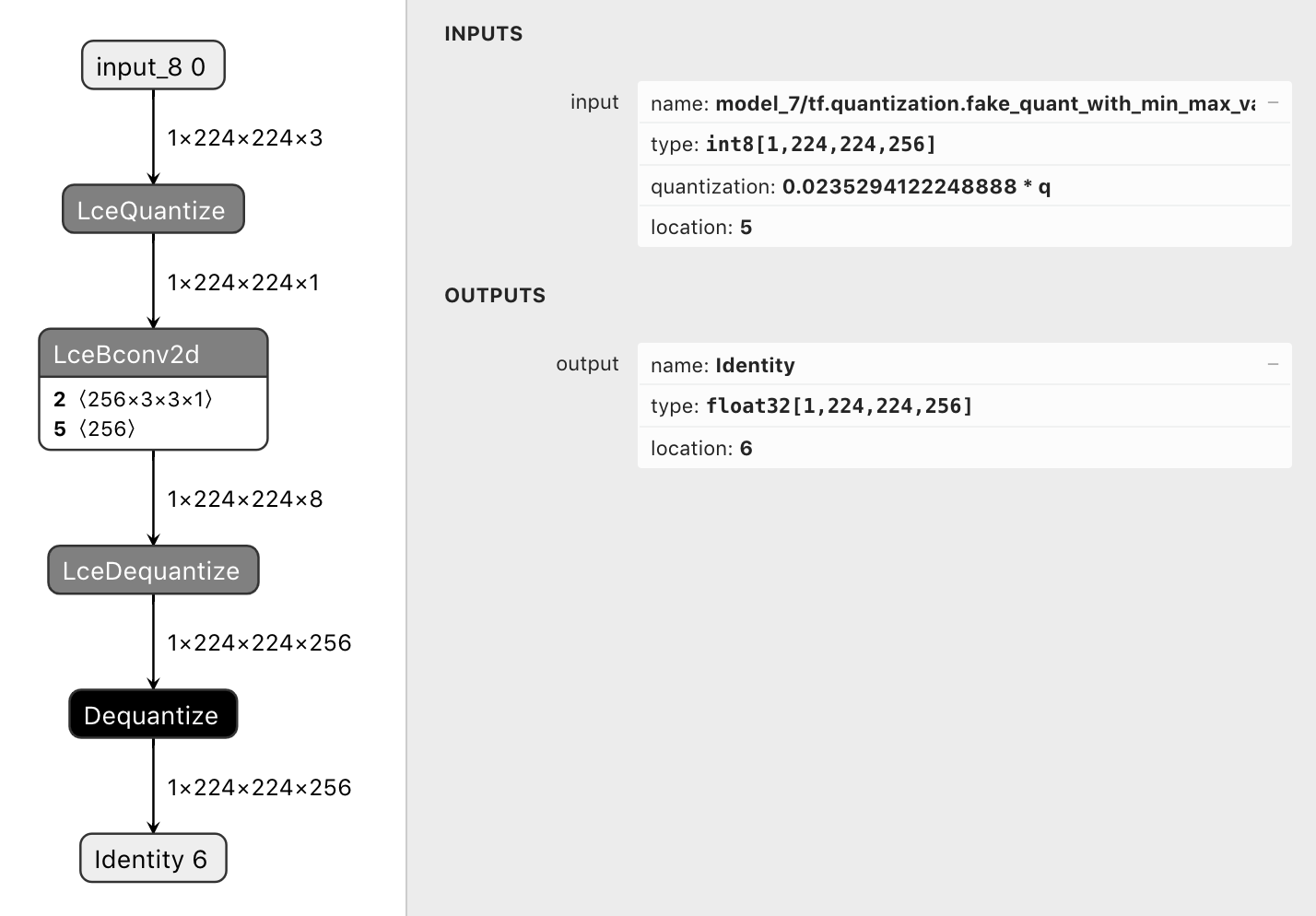
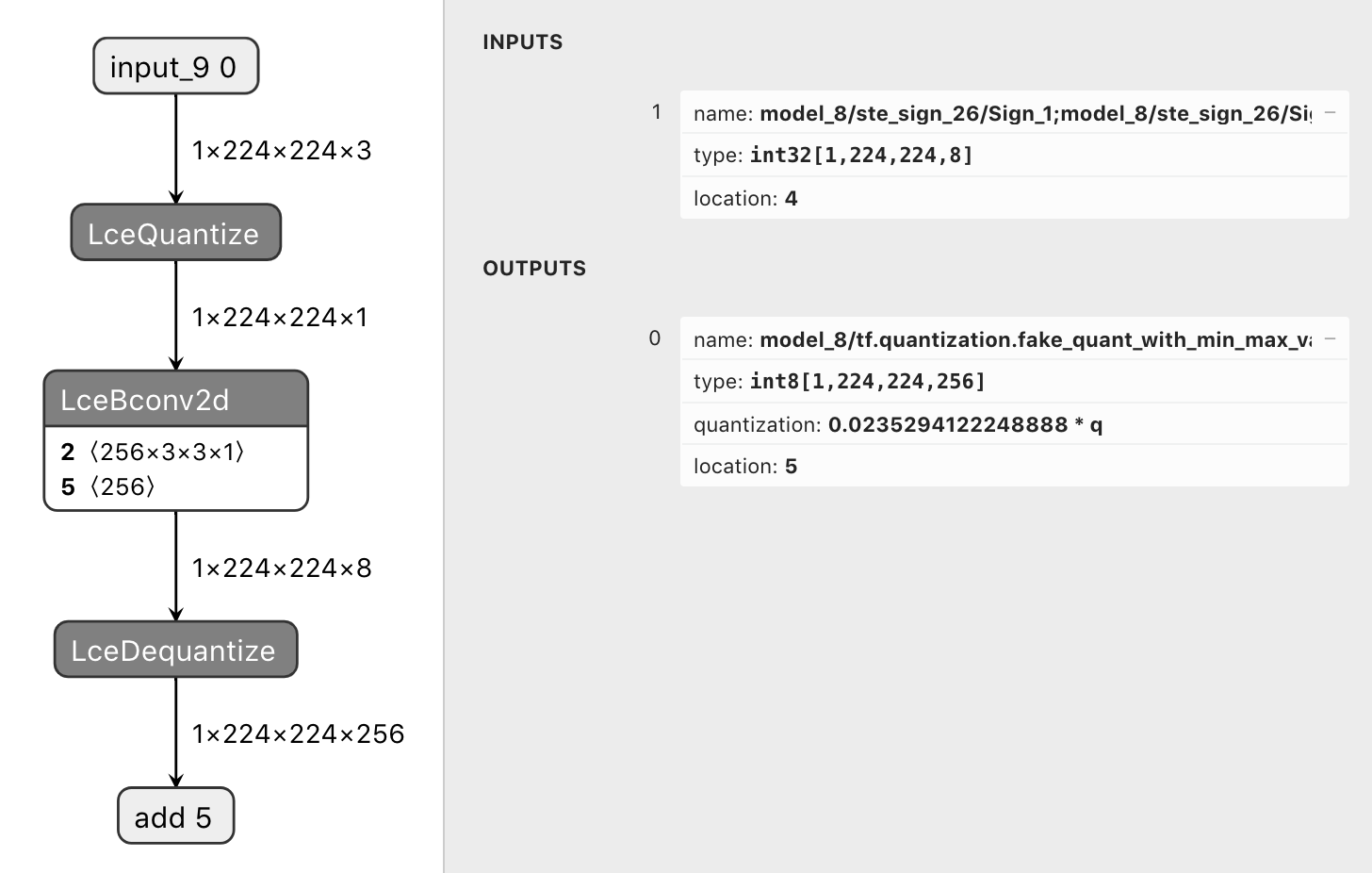
- fake quantize before QuantConv2D
… experimental_enable_bitpacked_activations
strip_lcedequantize_ops: strips the output LceDequantize operators of a model such that the output is a bitpacked tf.int32 tensorWhat do these changes do?
Usually the lce_converter dequantizes the bitpacked output back to
tf.float32/tf.int8resulting in an identity tensor. This is intended for training. However for inference or postprocessing one could use the bitpackedtf.int32tensors directly.By using
strip_lce_dequantize_opsone can strip the output LceDequantize operators of a model to get access to the bitpacked tf.int32 tensors.Use cases: larq.layers.QuantConv2D followed by a sign operation (ie. larq.math.sign or larq.quantizers.SteSign())
Update
Works for tf.float32 as well as for tf.int8 quantized models.
Strips Dequantize ops too if any, ie. due to dequantization when using inference_output_type=tf.int8
How Has This Been Tested?
Related issue number
#599