Fix BaseCV objects early crashes #897
Conversation
|
Hi @mfeurer, can you do a small code review? I think the problem is now fixed. Thank you! 962 y = D.data['Y_train']
963 shuffle = self.resampling_strategy_args.get('shuffle', True) |
|
Hey @charlesfu4 I'm currently busy attending the ICML conference. I'll do my best to have a look at this PR next week. |
Codecov Report
@@ Coverage Diff @@
## development #897 +/- ##
===============================================
- Coverage 84.98% 84.89% -0.10%
===============================================
Files 128 128
Lines 9439 9442 +3
===============================================
- Hits 8022 8016 -6
- Misses 1417 1426 +9
Continue to review full report at Codecov.
|

Thanks a lot, hope you enjoy it! By the way, do you know why my codecov build keeps staying at 2 month ago? Is it a normal bug or just something I forget to set up? |
There was a problem hiding this comment.
Hey @charlesfu4 thanks for looking into this. Your approach would most likely work, but I was wondering where these additional variables came from and found that one needs to update parts of the code for the latest SMAC version. I created a new PR here #908 could you please have a look whether that fixes the original issue?
I believe your PR also adds extra code for handling multi-output regression, but that should be a different PR.
| 'LeaveOneOut': {}, | ||
| 'LeavePOut': {'p': 2}, | ||
| 'PredefinedSplit': {}, | ||
| 'PredefinedSplit': {'test_fold': [0, 1, 2, 3]}, |
There was a problem hiding this comment.
Could this also be an empty list?
There was a problem hiding this comment.
PredefinedSplit with empty list will return no index(None) after split, so I do not think it will work.
| 'for chosen CrossValidator.') | ||
| try: | ||
| if self.resampling_strategy_args['groups'].shape != y.shape: | ||
| if self.resampling_strategy_args['groups'].shape[-1] != y.shape[-1]: |
There was a problem hiding this comment.
Could you please let me know when this fails? Also, could you please update the error message?
There was a problem hiding this comment.
With removing the ravel above, shape[-1] represents the number of samples whatever type of target it is. It fail when there is a for example multi-output regression target with n_samples = 100, n_targets = 3. If we keep the ravel in line 912 and keep line 925 as shape. The 'groups' we have to define is (300,) in shape. There, however are only 100 samples which led to this error message.
[ERROR] [2020-07-22 22:27:55,917:AutoML(1):d4069f363ae29ee607f565032a35aa5f] Error creating dummy predictions:
{'traceback': 'Traceback (most recent call last):\n File "/home/charles/anaconda3/envs/autoskdev/lib/python3.7/site-
packages/autosklearn/evaluation/__init__.py", line 29, in fit_predict_try_except_decorator\n return ta(queue=queue,
**kwargs)\n File "/home/charles/anaconda3/envs/autoskdev/lib/python3.7/site-
packages/autosklearn/evaluation/train_evaluator.py", line 1239, in eval_cv\n
.fit_predict_and_loss(iterative=iterative)\n File "/home/charles/anaconda3/envs/autoskdev/lib/python3.7/site-
packages/autosklearn/evaluation/train_evaluator.py", line 446, in fit_predict_and_loss\n
groups=self.resampling_strategy_args.get(\'groups\')\n File "/home/charles/anaconda3/envs/autoskdev/lib/python3.7/site-
packages/sklearn/model_selection/_split.py", line 327, in split\n X, y, groups = indexable(X, y, groups)\n File
"/home/charles/anaconda3/envs/autoskdev/lib/python3.7/site-packages/sklearn/utils/validation.py", line 248, in indexable\n
check_consistent_length(*result)\n File "/home/charles/anaconda3/envs/autoskdev/lib/python3.7/site
-packages/sklearn/utils/validation.py", line 212, in check_consistent_length\n " samples: %r" % [int(l) for l in
lengths])\nValueError: Found input variables with inconsistent numbers of samples: [100, 100, 300]\n', 'error':
"ValueError('Found input variables with inconsistent numbers of samples: [100, 100, 300]')", 'configuration_origin':
'DUMMY'}
I have tried it manually here and a clearer version is shown in the photo.
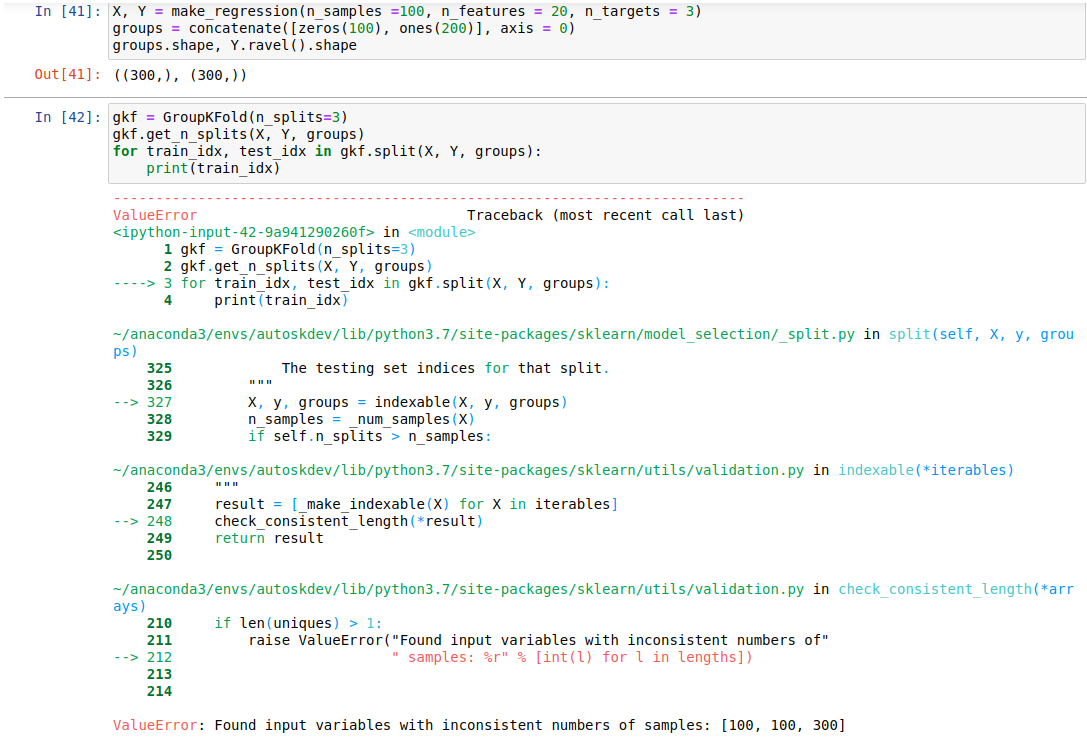
| else: | ||
| if 'groups' in self.resampling_strategy_args: | ||
| if self.resampling_strategy_args['groups'].shape != y.shape: | ||
| if self.resampling_strategy_args['groups'].shape[-1] != y.shape[-1]: |
|
Hey @charlesfu4 I just merged #908 to allow custom resampling strategies. As you said, this PR also allows using multi-output regression with custom resampling strategies. Would you like to create a new PR allowing custom resampling strategies for multi-output regression? |
Sure, thank you! I will do it soon. |
* Fix #897 - allow groups strategy cv on multi-output regression * Fix classification * Fix coding length. * fix single_reg missing ravel * Revert "fix single_reg missing ravel" This reverts commit 66f95c0. * Fix single_reg ravel missing * Fix flake8 warning * Unittest updated for get_splitter of regressions * Fix letters cast to lower-case * Fix letters cased to lower-case 2 * Asserts functions updated.
When specifying customized cross validation objects, AutoML process tends to crash in its early stage.
The corresponding debug message shown below
It is basically caused by deepcopying resampling_strategy_args into init_dict in train_evaluator.py. It obtains extra parameters that are not for initializing cross validation objects. Therefore, I did some modification to make sure init_dict only contain defaults arguments defined in the beginning of train_evaluator.py. Besides, due to the change mentioned, PredefinedSplits also got default arguments to avoid failure in unit test.
The results of same resampling_strategy for example KFold and 'cv' should get the same results with same arguments and seeds. However, they have quite different outcomes in cv_results_, pipeline, and hyper-parameters in the end('cv' apparently overfitted and KFold did not). Not sure what caused this. I will do more research on it later this week.