The mean_kl implementation is different from that of openai/lm-human-preference #438
Description
🐛 Describe the bug
Currently, the mean_kl used to update kl_ctl is calculated from:
trlx/trlx/trainer/accelerate_ppo_trainer.py
Lines 437 to 438 in 92b68e4
which is a mean value over each token.
While in openai/lm-human-preferences, the
mean_kl is:
kl = data['logprobs'] - data['ref_logprobs']
mean_kl = tf.reduce_mean(tf.reduce_sum(kl, axis=1))(https://github.com/openai/lm-human-preferences/blob/bd3775f200676e7c9ed438c50727e7452b1a52c1/lm_human_preferences/train_policy.py#L220-L221)
which is not only the mean value upon each response, but also the same form of the kl used in reward.
Also, in anthropic's paper Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback, their kl value could be as large as 25 (as the square root is 5), which is hard to achieve for a token-wise mean kl.
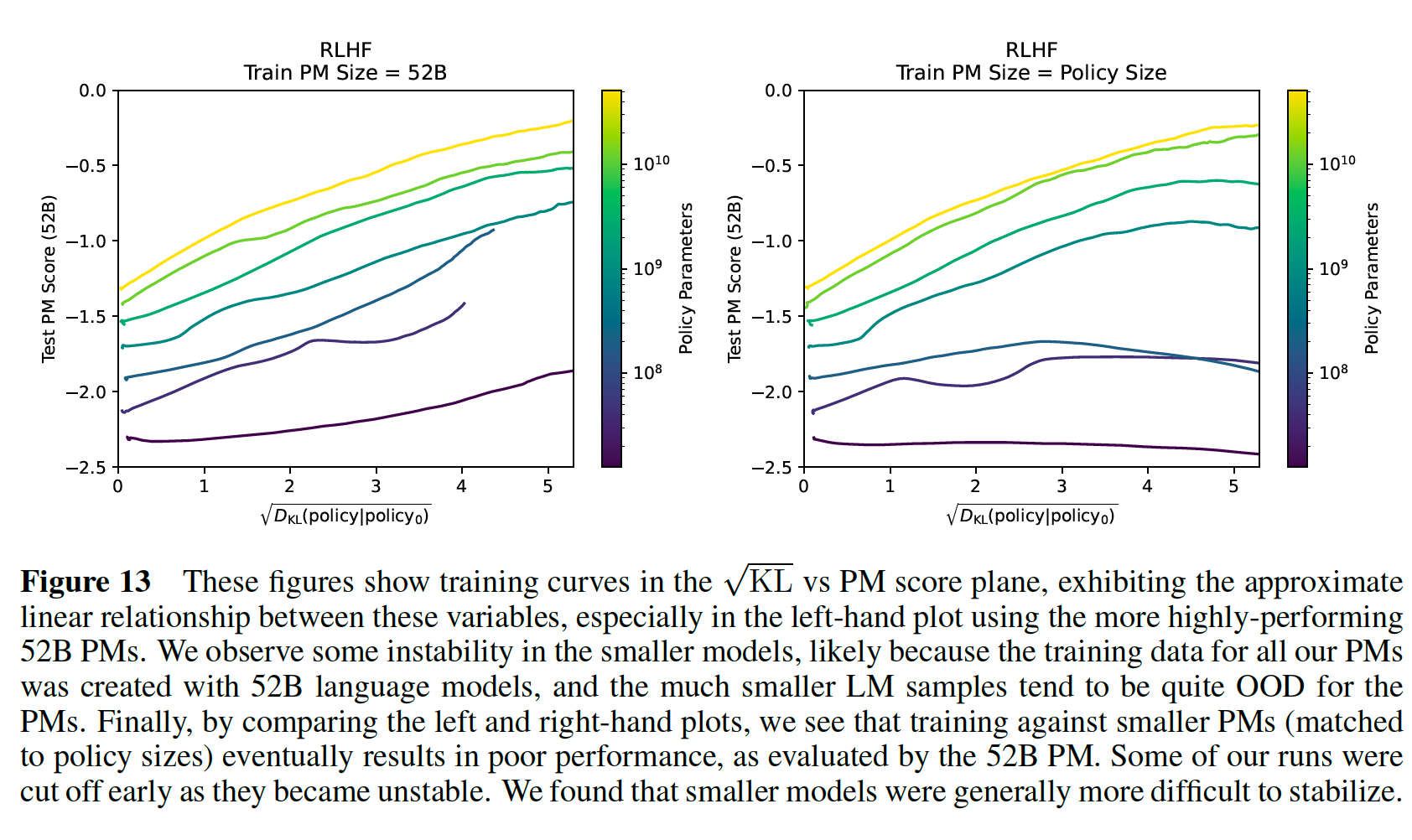
I wonder if there is a specific reason why we use the current form of mean_kl? Thank you!
Gently ping @Dahoas @reciprocated
Which trlX version are you using?
No response
Additional system and package information
No response